2.2 KiB
What?
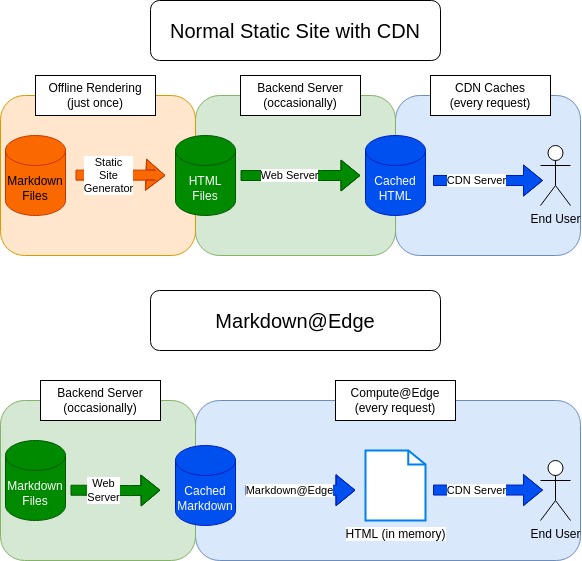
This page is written in Markdown (actually in three Markdown files).
These Markdown files are requested by Fastly's Compute@Edge engine and rendered into HTML at the edge, on every request.
You can check out the source code here.
The only dependency of the service, other than the Fastly SDK,
is Raph Levien's pulldown-cmark.
It's not an optimal choice, as it only supports one-shot rendering and requires buffering
the Markdown (though not the resulting HTML) in memory, but it's the best option available
at the moment.
The renderer takes advantage of the fact that Markdown allows embedding raw HTML by embedding anything with a "text" MIME type in the Markdown source, while passing through anything without a "text" MIME type - images, binary data, and so forth - unchanged.
That allows the above JPG image to embed properly, while also allowing the linked SVG image page to be rendered as a component of a Markdown document.
Why?
I work on the Compute@Edge platform and wanted to get some hands on experience with it. This is not a good use of the platform for various reasons; among other things, it buffers all page content in memory for every request, which is ridiculous.
A static site generator like Hugo or Zola is an objectively better choice for bulk rendering, while the C@E layer is better for filtering, editing, and dynamic content.
That said, this does demonstrate some interesting properties of the C@E platform. For instance, the source files are hosted in a subdirectory of my webserver; in theory, you could directory-traverse your way into my blog source, but in fact, you can't.
I also have a Clacks Overhead set for my webserver, and the C@E platform is set up to make passing through existing headers trivial even with entirely synthetic responses like these, so that header is preserved.